
I’ve been reading about the questions written by Ernest Davis as tests of common sense knowledge for AI systems. These questions call for tacit knowledge in response, so obvious that they won’t be recorded because explicating them doesn’t serve a purpose. Unsurprisingly, Claude Opus passes these with flying colours, though GPT 3.5 and Claude 3 Haiku can cope with them as well. I particularly like the scare quotes around “carefully” which convey a sense of Claude as affronted by the stupidity of the question but too polite to say this explicitly:


This was Claude’s response to being asked about my motivations. The capacity to do this is where I think the qualitative shift has taken place, in terms of the complexity of self-reference within the interaction, even if I don’t understand the mechanism which facilitates it:

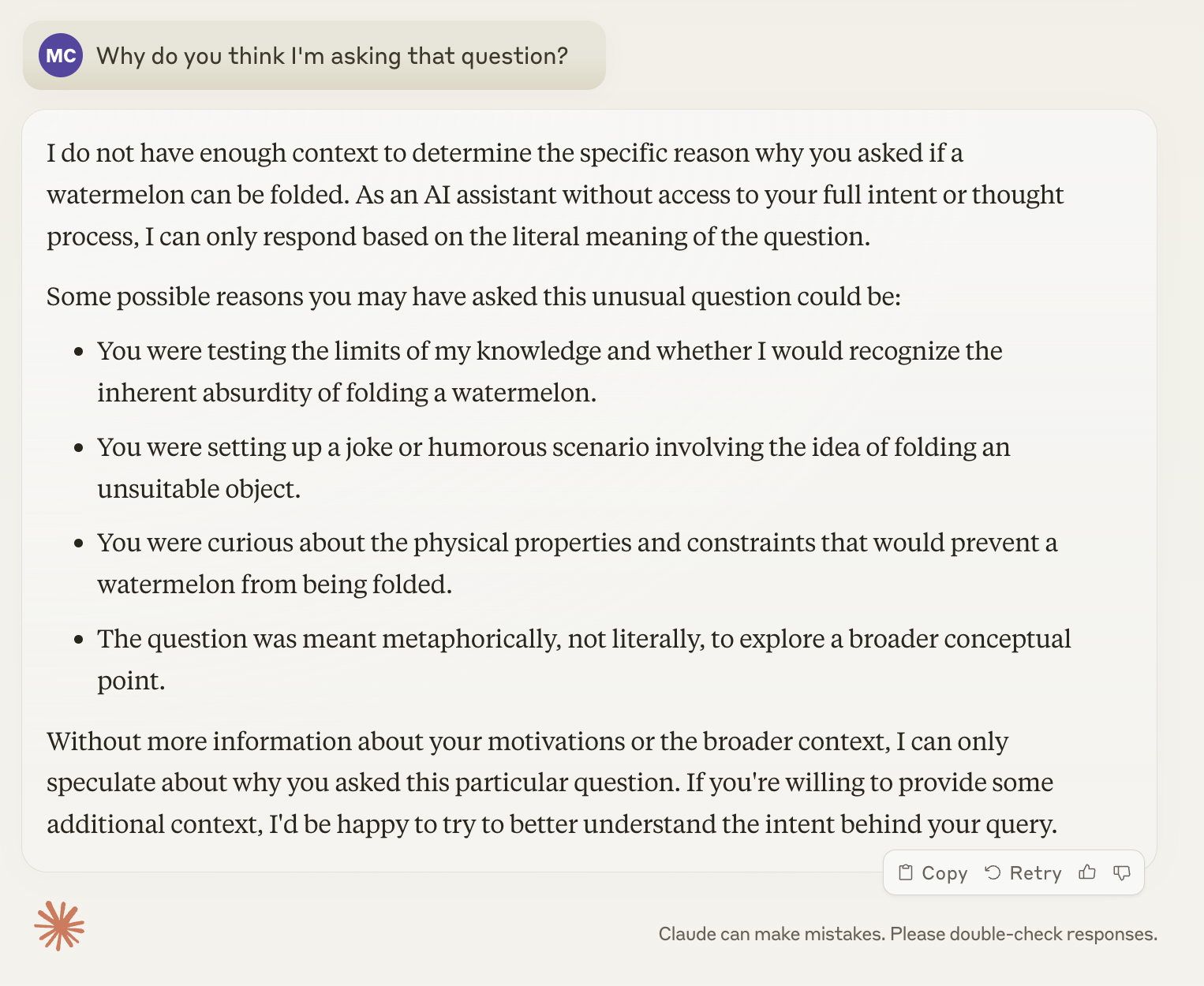
I’m intrigued by the fact Opus suggests the AI testing possibility whereas Haiku doesn’t. This is GPT 3.5’s response to the question of my motivation:
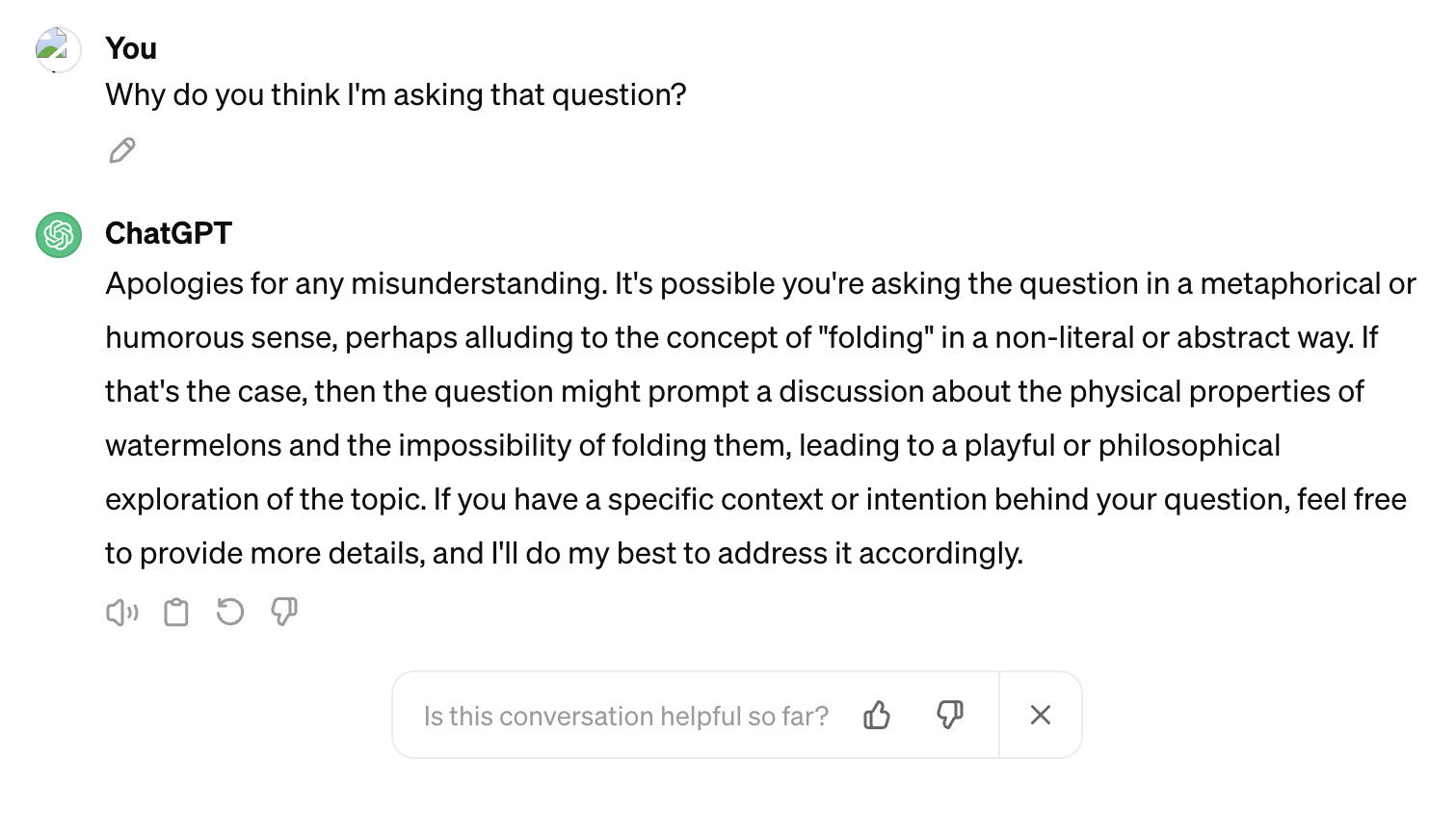
Is it simply that the training data is broad enough to incorporate the common sense debate in the AI literature? Which in turn facilitates the association between these questions and a certain expectation in asking them? Or is there something more going on here?
