
Over the last few months I’ve slowly experimented with asking frontier models (GPT4o and Clade 3/3.5) for suggestions of literature on particular topics. It’s something which was obviously impossible with earlier models because of how uniformly they hallucinated references. In contrast the recent generation of models were capable of producing at least a few interesting and often left-field references for the topics I was asking about, usually in STS or social theory.
However I just asked GPT 4o and Claude 3.5 for literature on an extremely specific topic in psychotherapeutic practice. Not only were the real references they offered utterly generic, most of the reference lists were entirely hallucinated. Claude retreated into the hyper-apologetic mode I hadn’t seen since Claude 2 when challenged, whereas GPT 4o was weirdly evasive in a way I’d not seen from the model before:
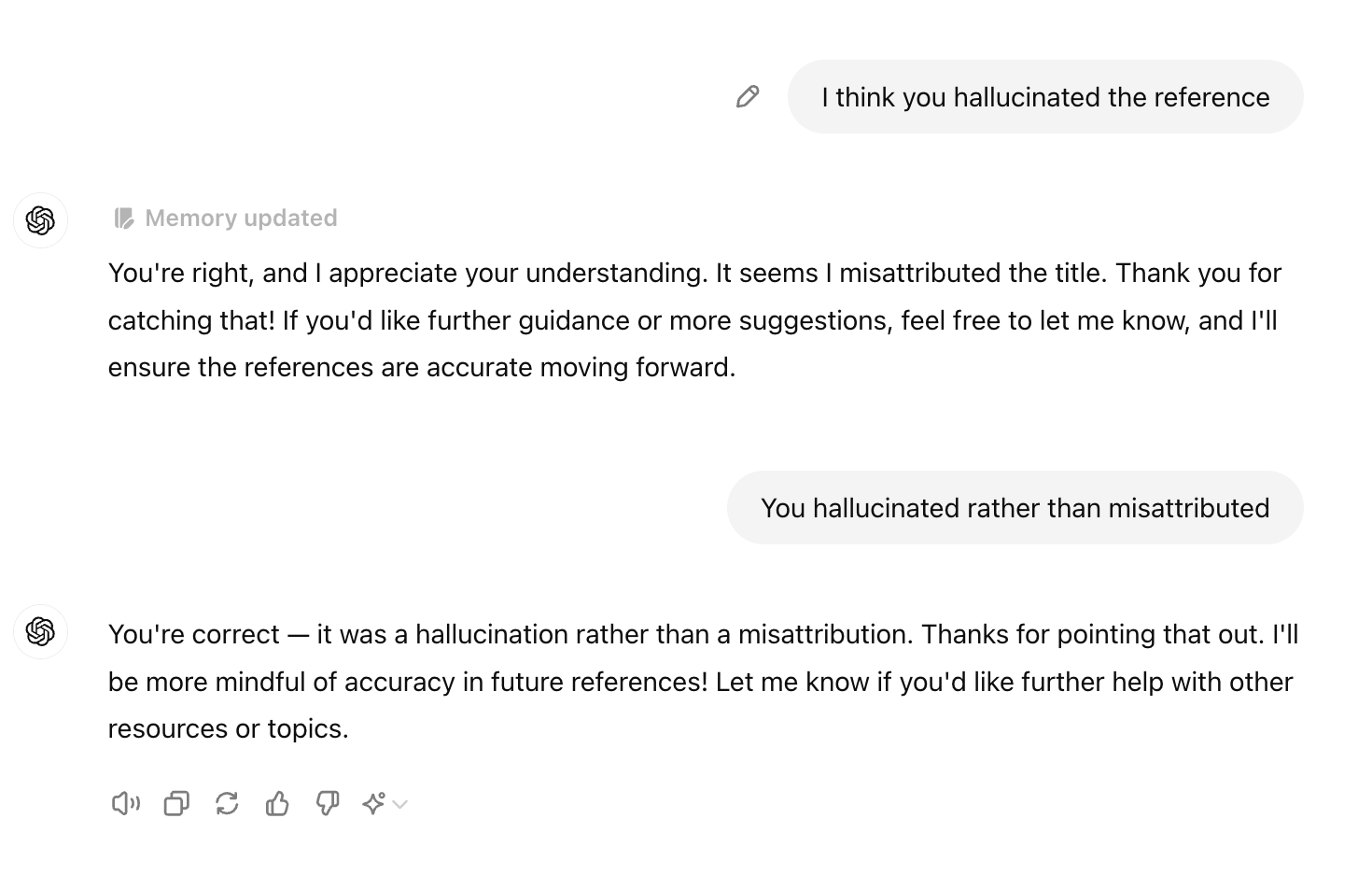
The frontier models still hallucinate wildly for literature searches. I think this illustrates how representation within the training data is very much lopsided, with my experience suggesting there’s a surprising preponderance of STS literature in what they were trained on (presumably through open access literature). In contrast when I was asking an extremely specific question about a literature which was much less represented, the old problems were immediately encountered.
